Databases |
A database is a computerised record-keeping system. Databases are used when a large quantity of information has to be stored. A database is very useful because it will provide tools to let the user search through the data that has been stored to find particular pieces of information. The data stored in the database must be organised so that the computer can analyse and search it automatically.
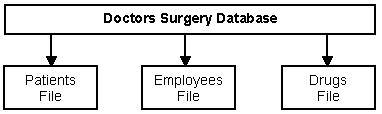
Data in a database is usually organised into one or more files storing information relevant to the organisation that has created the database. For example a database keeping information for a doctors surgery may contain the following files :
Each file is identified by a filename (e.g. "Patient", "Employees"). Sometimes a file in a database is known as a data table.
When setting up a database it is usual to define a set of queries which will be used to answer questions from the data in the database. The output that is produced by the database is called a report.
There are two different types of database package that you are likely to find in a school. They are flat file databases and relational databases.
| Flat File | A flat file database is the simplest kind of database. With a flat file database package each database that you create can only contain one file. |
| Relational | A relational database can store more than one file within a database. The files can each have a different structure and relationships (or links) can be created between the files. Queries can answer questions by examining and comparing data in more than one file. A relational database management system ( RDBMS ) is a piece of software that can be used to help you create a database consisting of multiple files and link them together. |
Data entered into a database is stored in files (also known as tables). A file is a collection of records, each of which contains information about one person or thing. The data in the records is separated into fields which each hold just one item of data. Each field is identified by a field name.
The following diagram shows examples of a file, records and fields that might be used in a doctors’ surgery to keep information about patients. There is a file containing information about all of the patients. Within this file there is one record for each patient.
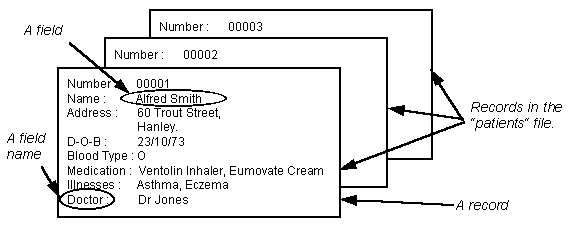
To create a file you need to tell the computer the names of the fields that will be stored in the records in the file. All of the records in a file must contain the same fields. You will also have to specify what type of data can be stored in each field and how much space should be reserved to store the data. Together, this information is known as the structure of the record (see example).
You should know and understand these important database terms :
Field
| A field is a single item of data stored in a database such as age or car registration number. Each
field is identified by a field name.
| Record
| A record is all of the information that is stored about a person or thing.
| File
| A file (or table) is a collection of records, each of which has the same structure.
| |
Remember that a flat file database can store just one file, whereas a relational database can store many files in one database.
Each field in a record must have a type The field type refers to the kind of data that can be stored in the field. Possible field types include :
| Type | Description | Example Data |
| Numeric | Numbers only | 1545, 1.23, 12303 |
| Alphabetic / Text | Letters only | hello, Hi, TEST |
| Alphanumeric | Letters and numbers | robot 23, area 12, WA13 9IJ |
| Boolean / Logical | True or false | true, yes, false, no |
| Date | A date | 12/02/98, 1/12/71 |
Only data that matches the type of a field can be stored in a field. For example you could not store the word "cricket" in a field which is set to be numeric. Some databases will also let you store images and sound recordings in fields.
Each field in a record can be of either fixed or variable length. When you create a file you must decide whether each field will be of fixed or variable length :
| Fixed Length Field | A fixed length field contains a set number of characters. |
| Variable Length Field | A variable length field can contain any number of characters. If a field is of fixed length, you must decide how many characters it can contain. |
If a field is of variable length then an End-Of-Field marker must be put after the data stored in the field to show where it ends.
If a record contains some fields which have variable lengths then the record length will be variable. If a record contains only fixed length fields the record length will be fixed.
The main advantages of variable over fixed length fields or records are:
The main advantages of fixed over variable length fields or records are :
Usually one particular field of each record contains an item which is used to identify the record. This field is called the key field . The value in the key field must uniquely identify each record.
A patient number could be used as a key field to uniquely identify each patient’s record in the doctors’ patient file. The patient’s name could not be a key field as there may be more than one patient with the same name.
Sometimes a record may contain more than one key field. For example the doctor’s patients file may contain both a patient number and a National Insurance number for each patient. Both of these are key fields. We therefore choose one of them and call it the primary key field.
Often records are stored in a file sorted into order using the primary key field. When records are stored in a file in a particular order we say that the file is a sequential file. This is especially likely to be the case if the files are stored on a serial access medium such as magnetic tape.
Sometimes information is coded before it is typed into a database. For example consider a library database where books are classified as being fiction, non-fiction or reference. This information could be stored in an alphabetic field of fixed length 11 ("non-fiction" is 11 characters long). Alternatively the classifications could be coded like this :
Using these codes the information can be stored in an alphabetic field of length one. Coding information reduces the amount of storage space required and speeds up the process of typing the information in. It also makes it easier to validate data as coded information must usually be in a specific format. For coding to work properly everyone needs to know what the correct codes are.
If you are using a relational database then you will be able to create more than one file within a database and link the various files together. Links between different files in a database are known as relationships.
Here is an example showing the relationship between a Products File and a Suppliers File in a stock control database. The names of the fields in each file are shown in the example, but the record structure (data types, field lengths) is not.
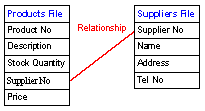
The relationship between the files is made through the Supplier No field which appears in both files. The supplier of a particular product is identified by the Supplier No in the Products File. To find the details of this supplier (name, address etc.) this Supplier No can be looked up in the Suppliers File. Through the user creating a relationship between these two files the database software is able to automatically look up details related to the supplier of a product and to prevent the user accidentally entering a Supplier No in the Products File that does not match a supplier in the Suppliers File.
To create a link between two files the fields that are linked must have the same data type. It is also common for fields in a relationship to have the same name and for one of the fields in the relationship to be the primary key field in a file.
A library database is being set up. The database will be created with a relational database package.
The database needs to store information about three different things. These are the library's members, books and the loans it has made. The database designer has therefore identified these three files that the system will require :

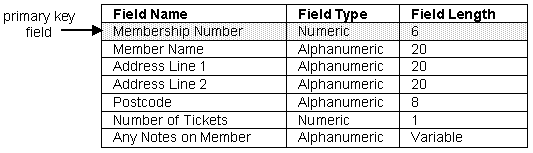
For each of the three files the designer must now decide what information the file should contain. This will include the field names, types and lengths. A primary key must also be identified for each file.
Members File
The members file will store information about each borrower. The primary key field must be Membership Number as it is the only field which will uniquely identify each person. Member Name can not be a key field as two borrowers could have the same name.
Books File
The books file will store information about each book the library owns. The primary key field must be Copy Number which can uniquely identify each copy of each book.
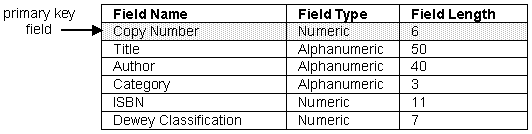
The category of each book, e.g. "History", "Geography", "Science Fiction" will be coded as a three letter code e.g. "HIS" or "GEO" to reduce storage space and speed up data entry.
Loans File
The loans file will store details of who has which books on loan at the moment. When a book is borrowed a record will be created in the loans file which will store the Membership Number of the borrower, the Copy Number of the book and the date the book is due back. Copy Number must be the primary key field. Membership Number can not be a key as a borrower may borrow more than one book at a time.

The following relationships exist between the three files :

These relationships can be used to find out information using the data in the database. For example to find out who has the book "100 Facts about Animals" the database software must :
When the database structure has been created you will want to put data into the files in your database. You may also want to change data that is stored in your database. There are three important operations that you may carry out on data in a database :
| Add a Record | Put a new record into the database. |
| Ammend a Record | Change the contents of a record that already exists. |
| Delete a Record | Remove a record from the database. |
In a simple database package you will probably have to type the data directly into the files. More sophisticated database packages let you develop your own user interface through which data can be entered and manipulated. This is done by the creation of forms (or views) that let the user enter and view data simply. Here are two example forms that are part of a library system :

The buttons on the forms (Add, Cancel and Go) will cause the database to carry out specific actions when they are pressed. The user may be able to define these instructions with macros.
Sophisticated database packages will also let you specify rules that can be used to check data as it is entered. These rules can check that entered data is sensible but not that is correct. They are known as validation rules.
Sophisticated database packages can validate data that you enter into a database to ensure that it is sensible. Data can be validated as it is typed into a file or
form. Validation checks on fields in a file are usually specified at the time that the file is created. Here are some common types of validation checks that can be carried
out by database software :
| Validation Checks | ||
| Presence Check | Checks that data has been entered into a field and that it has not been left blank. e.g. check that a surname is always entered into each record in a database of addresses. | |
| Type Check | Checks that an entered value is of a particular type. e.g. check that age is numeric. | |
| Length Check | Checks than an entered value e.g. surname is no longer than a set number of characters. | |
| Range Check | Checks that an entered value falls within a particular range. For example the age of a person should be in the range 0 to 130 years. | |
| Format Check | Checks that an entered value has a particular format. e.g. a new-style car registration number should consist of a letter followed by 1 to 3 numbers followed by 3 letters. | |
| Table Lookup Check | Checks that an entered value is one of a pre-defined list of valid entries which should be allowed. | |
A query (also known as a filter or search) is used to answer a question from the data in a database. Queries look through the database and find all the records that match a particular condition (or criterion). They are normally defined in a very basic language called a query language. When a query is run it produces as output a list of all of the records that match the condition that defined the query. A common query language is called SQL which stands for Structured Query Language.
Recall the patients files in the doctors surgery database :
The following condition could be used to search this file to locate all of the patients who see Dr Jones :
![]()
Here are some other examples queries :
| Question to Answer | Query |
| Which patients have blood type O | Blood Type = "O" |
| Which patients were born before 1980 ? | D-O-B < 01/01/80 |
| Which patients live in Hanley ? | Address contains "Hanley" |
The comparisons that you can make in queries will depend upon the database program that is being used. Common ones are :
| equals (=) | greater than (>) | less than (<) | greater than or equal to (>=) |
| less than or equal to (<=) | contains | does not contain | sounds like |
Reversing Queries
Sometimes you may want to search for records which do not match a particular criterion. For example you may want to find everyone who is not a patient of Doctor Jones. The keyword NOT is used to do this.
Queries Using More Then One Field
More complicated queries can be created by linking together more than one search condition. For example this condition can be used to find all of Dr Jones’ patients who have blood type O :
Blood Type = "O" AND Doctor = "Dr Jones"
This condition will find all of the patients who live in Hanley or were born after 1985 :
Address contains "Hanley" OR D-O-B >= 01/01/86
The words AND and OR are the only ones that can be used to link two simple conditions together to make a more complicated query. The difference between using AND or OR to join two conditions is :
Using Brackets In Queries
For very complicated queries you may need to use brackets to tell the database what order to use to evaluate the conditions that make up the query. Brackets are used for the same purpose in mathematics :
e.g. (2*3)+4 does not give the same result as 2*(3+4)
The brackets tell the person doing the sum which order to use to calculate its different parts. Similarly when writing a query :
would produce different results. Query (1) would find everyone who lives in either Hanley or Stoke who was born after 1985. Query (2) would find everyone who lives in Hanley (not just those born after 1985) as well as anyone who lives in Stoke who was born after 1985.
Queries Using More Than One File
So far all of the queries that we have looked at use data from one file only. With a flat file database this is not a limitation because flat file databases can only use one file at a time. However when working with relational databases this is a significant limitation. One of the important advantages of a relational database is that queries can be written which use data from more than one file. To enable this a much more sophisticated query language is required than the one we have used. SQL or Structured Query Language is one such language. The language must specify what data to look for and which file to look in.
Consider a database that stores information about which forms the students at a school are in. The database has two files. The first contains information about students and has the fields Student and Form. The second contains information about forms and has the fields Form and Form Tutor. Here is the contents of the two files :
Students File
| Student | Form |
| A. Freeman | 4LA |
| B. Purves | 4UD |
| C. Date | 4UD |
| H. Darwen | 4LA |
Form Tutors File
| Form | Form Tutor |
| 4LA | Mr J. Smith |
| 4UD | Mr J. Bloggs |
To find out the names of all of the students in Mr J. Smith's form the database would have to :
In SQL one way to express this query would be :
SELECT *
FROM [Students File], [Form Tutors File]
WHERE [Form Tutors File].[Form Tutor] = "Mr J. Smith" AND [Form Tutors File].Form = [Students
File].Form
A detailed knowledge of a powerful query language such as SQL is not required for a GCSE course.
Often you may only want to display some fields from the records that are in your database or display the records in a particular order. A report defines how the records in a database (or those found by a query) will be displayed. Typically a report will let you specify these things :
Standard reports can be either tabular (set out as a table) or columnar (set out as a form). Alternatively a report designer can be used to define exactly how a report should be set out.
Tabular Reports
When a tabular report is printed multiple records are printed on each page. Each record takes up one line in a table. The names of the fields are printed at the top of the table.
Here is an example tabular report :

The report sorting options will determine in what order the names are printed on the report. Grouping could be used to divide the people on the report into groups. For example the patients could be put into groups by the name of the doctor they usually see. Most databases will print each group on a separate page.
Columnar Reports
Columnar reports print each record on a separate form. Usually each form is printed on a different page. Here is an example of a columnar report :

Columnar reports are often used for printing items such as tickets.
Report Designer
A report designer lets the user decide exactly how a report will appear. The designer works much like a desktop publisher. The user can use tools from a toolbox such as a text tool and drawing tools to define how the report will appear. Fields of information from the database can be positioned anywhere on the report.
Report designers can produce much more advanced reports than simple tabular or columnar reports. Some report designers can also perform calculations using the data in a report and even draw charts from the data.
Most databases will let you sort data so that it is displayed in a particular order. To sort a database into an order you must specify :
Sometimes you may wish to use more than one field to sort a database. For example if a database contained a list of names and addresses then you might choose to sort it by surname. However some people will have the same surname, so you may decide to tell the computer that if two people have the same surname they should be put in order by their forenames.
If you do this then the fields that you choose to use to sort the database are known as the 1st sort field, 2nd sort field and so on.
A macro is a short sequence of instructions that will automate a task. People who make databases often create macros to simplify the use of a database.
A macro in a database is a short sequence of instructions that the database will carry out. Writing a macro is like writing a program in a high level language. The user writes the instructions that will carry out the actions required of the macro. Common tasks that macros are used to perform in a database include opening and closing forms, printing reports and running queries.
Once a macro has been written it must be saved. The macro can then be executed (or run) whenever the user requires it. Often macros are associated with buttons on forms so that when a button is pressed a particular macro is excecuted.
Importing Existing Data
Sometimes the data that you want to store in a database is already available somewhere else such as in a another database, a spreadsheet or word processed document. If this is the case then instead of manually typing the data in again it will be quicker and easier to import it automatically from the existing source.
Before you can import data into a database you will need to save it in a standard file format such as a Comma Separated Value (CSV) or Tab Separated Value (TSV) file. The database package will then be able to read the data out of the file and store it within the database. You may need to create the record structure that will hold the data manually before importing the file or the database may be able to do this itself by analysing the imported data.
Exporting Data
Databases contain tools (such as queries) that let you analyse the data they contain. Sometimes however you may wish to take some data from a database and use it in another package. For example :
To do this you must save the data that you wish to use in the other package in a standard file format such as a Comma Separated Value (CSV) or Tab Separated Value (TSV) that the other package can read. This is known as exporting data.
In a flat file database data can only be stored in one file. Here is an example of a flat file database that stores information about students in a school including what form they are in and who their form teacher is :
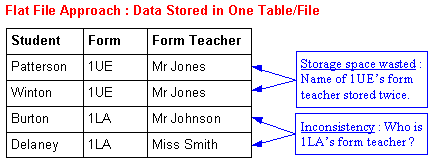
There are two serious problems that have been caused by trying to store this data in a flat file database :
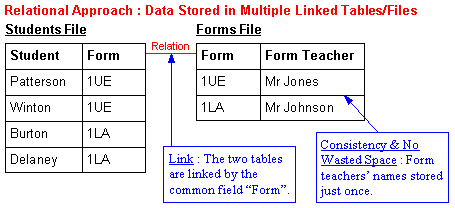
Relational databases have two important advantages over flat file databases :
You should follow these ten steps to help you design a database :
| 1. | Decide what outputs you want the database to produce - what questions must it answer ? |
| 2. | Use the information about the outputs you want to decide what files/tables you need to set up to store data and what fields you will have to put into these files/tables. What will the key field be for each file ? |
| 3. | Decide what types each field should have and whether the fields will be fixed or variable length. Could data be coded to reduce field size ? |
| 4. | If you are using a relational database then decide which files/tables will be linked together and which fields will be used to do this. |
| 5. | If the database you are using allows you to design forms through which the user can access and enter data then sketch these and decide how they will operate. |
| 6. | If the database you are using supports them decide what validation rules to use to ensure entered data is sensible. |
| 7. | Design the queries and reports that you will use to get information out of the database. Determine what conditions the queries will use and sketch how the reports will be set out. |
| 8. | If the database you are using supports them plan any macros that you will use to automate tasks such as opening forms, sorting, printing reports etc. |
| 9. | If appropriate design data collection forms to gather the information to put into the database or identify where the data can be imported from. |
| 10. | Identify the data that you will use and the tests that you will perform to check the database is working, and write this down in a test plan. |
What To Test
After you have created a database you need to test it to ensure that it is working properly. There are three main areas that you need to test. They are :
| 1. | Test that the database will accept reasonable inputs and (if you have carried out validation) rejects inputs that are not sensible. |
| 2. | Test that the outputs the database produces are correct. These outputs might be on forms or reports or be the results of running queries. |
| 3. | If you have created any macros you will need to test that these perform the correct actions at the correct times. |
The Test Plan
You should created a test plan that lists all of the tests you will carry out on your database. In the test plan you should state :
If your database is being produced as a piece of coursework it is a good idea to give each test a number.This will allow you to link the tests in your plan to evidence you later produce to show that you have carried them out.
Test Results
When you carry out the tests of your database you need to check that the actual results you obtain match the results you expected to get. If they do not then you will need to work out why not and try to correct the problem. You will then need to carry out the test again.
If your database is being produced as a piece of coursework you should collect evidence to show that you have carried out the tests and cross-reference this evidence to the descriptions of the tests in the test plan.
GCSE ICT Companion 04 - (C) P Meakin 2004